Publications
This page is out-of-date. See my Google Scholar profile for and up-to-date list of my publications.
See my thesis for nearly 300 pages of light reading.
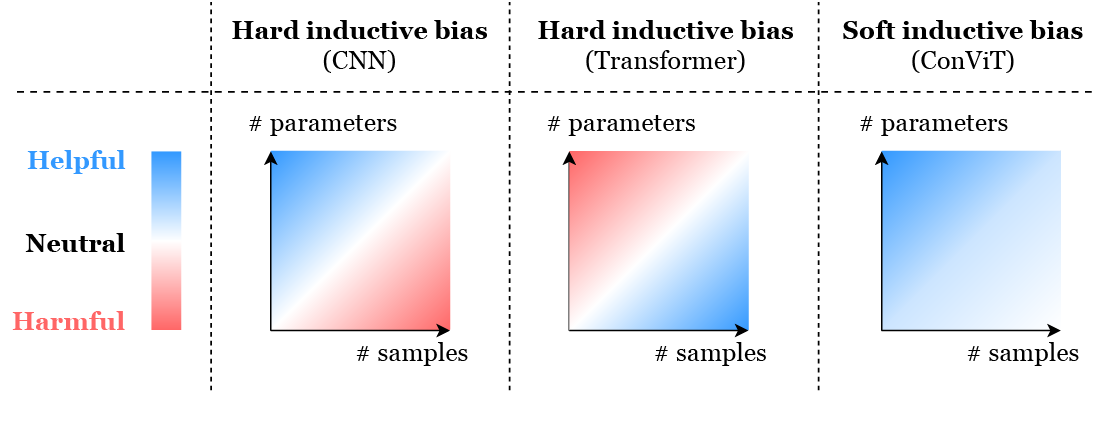
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
S d'Ascoli, H Touvron, ML Leavitt, AS Morcos, G Biroli, L Sagun
arXiv (2021)
To appear in ICML (2021)
Accessible abstract: The majority of progress in computer vision in the last decade has come from the use and refinement of convolutional neural networks (CNNs). The convolutional architecture enables sample-efficiency, but comes at the cost of a potentially lower performance ceiling. Transformers, a model architecture traditionally used for language tasks, have recently shown promise for vision tasks. Transformers are distinguished by their “self-attention” layers, which allow them to learn relationships between distant parts of their inputs, for example between the beginning and end of a sentence, or two opposite corners of an image. However these vision transformers (ViTs) require costly pre-training on large external datasets or teaching signals (for the experts: distillation) from pre-trained CNNs. In this paper, we sought to combine the strengths of these two architectures while avoiding their respective limitations. We accomplished this by adding a component to the self-attention layers of ViTs that performs convolution, but critically, the network isn’t stuck with convolution; it learns the optimal trade-off between convolution and traditional self-attention. We call this convolution-like ViT architecture ConViT. ConViT outperforms existing ViT models on multiple image classification benchmarks, and particularly excels when data are limited and/or models are large. We also examine the learning dynamics and inner workings of ConViT and other ViT models to better understand how they perform image classification.
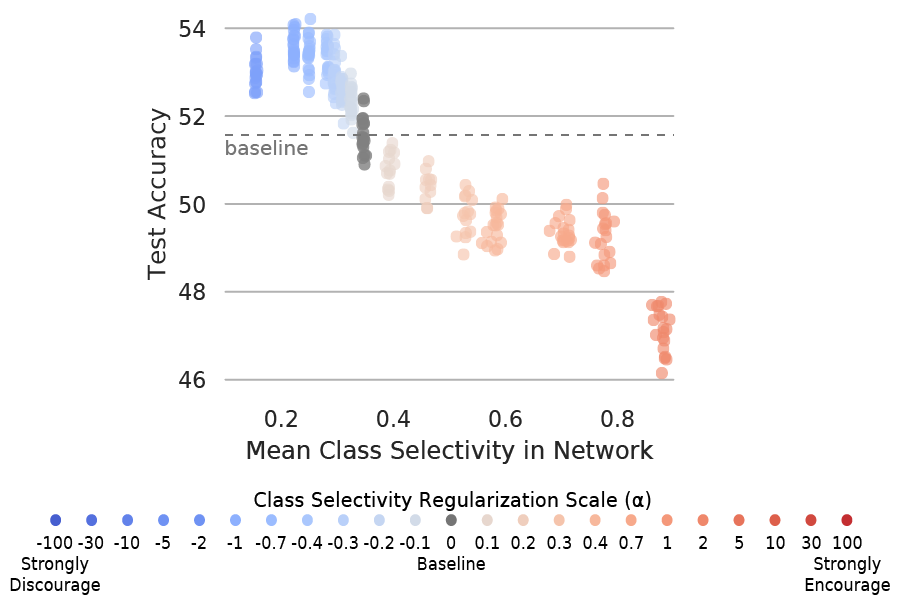
Selectivity considered harmful: evaluating the causal impact of class selectivity in DNNs
ML Leavitt, AS Morcos
ICLR (2021)
Also appeared in ICML Workshop on Human Interpretability in Machine Learning (2020)
Featured on the Facebook AI Blog: Easy-to-interpret neurons may hinder learning in deep neural networks
Accessible abstract: Our ability to interpret deep neural networks (DNNs) greatly lags behind our ability to achieve useful outcomes with them. One common set of methods for understanding DNNs focuses on the properties of individual neurons — for example, finding an individual neuron that activates for images of cats but not for other types of images. This preference for a specific image type is called “class selectivity”. However, it remains an open question whether DNNs actually need to learn class selectivity to function. We tackled this question through a new approach to manipulate class selectivity: When training a network to classify images, we not only instructed the network to improve its ability to classify images, we also added an incentive to decrease (or increase) the amount of class selectivity in its neurons. Surprisingly, we found strong evidence showing that DNNs can function well even if their neurons largely aren’t class selective. In contrast, we found that increasing class selectivity consistently caused networks to perform worse. These results indicate that class selectivity in individual units is neither sufficient nor strictly necessary, and can even impair DNN performance. They also encourage caution when focusing on the properties of single units to interpret DNN function.
Towards falsifiable interpretability research
ML Leavitt*, AS Morcos*
ML Retrospectives, Surveys & Meta-Analyses @NeurIPS (2020)
*equal contribution
Accessible abstract: Methods for understanding and interpreting deep neural networks (DNNs) typically rely on building intuition by using visualizations or focusing on the properties of individual data samples (e.g. images) or neurons. In this paper, we argue that DNN interpretability research suffers from an over-reliance on intuition that risks—and in some cases has caused—illusory progress and misleading conclusions. We identify a set of impediments to meaningful progress in interpretability research, and examine two case studies that highlight the ill effects of these impediments. We then propose a strategy to address these impediments in the form of a framework for strong, falsifiable interpretability research. Intuition is an indispensable first step, but it has just as much power to mislead as it does to enlighten. To fully understand AI systems, we must strive for methods that are not just intuitive but also empirically grounded.
Linking average- and worst-case perturbation robustness via class selectivity and dimensionality
ML Leavitt, AS Morcos
arXiv (2020)
Also appeared in ICML Workshop on Uncertainty and Robustness in Deep Learning (2020)\
Featured on the Facebook AI Blog: Easy-to-interpret neurons may hinder learning in deep neural networks
Accessible abstract: Deep neural networks (DNNs) deployed in the wild typically receive input data that aren’t quite as ideal as the benchmark datasets that most research gets conducted on in a lab environment. For example, consider the difference between identifying someone from a scanned passport photo vs. a photograph of a group of friends in a dimly-lit, chaotic bar. The noisiness of real-world data has motivated a lot of interest in understanding what makes DNNs robust to distorted inputs. Previous work of mine and Ari’s found that reducing class selectivity can improve DNN performance on clean images (see the summary of Selectivity considered harmful below). We sought to extend this work: does class selectivity affect robustness to distorted images?
We found that decreased class selectivity makes DNNs more robust against naturalistic distortions such as blur and noise. In contrast, we found that decreasing class selectivity decreases a different kind of robustness: robustness to targeted attacks in which images are intentionally manipulated in order to fool the DNN (adversarial attacks). Interestingly, the causal relationship between selectivity and both kinds of robustness is bidirectional: methods that improve naturalistic robustness also reduce class selectivity, and methods that improve adversarial robustness also increase class selectivity. Our results demonstrate a novel link between naturalistic and adversarial robustness through class selectivity (and representational dimensionality, but I’ll leave that part for the ML experts to read about in the paper).

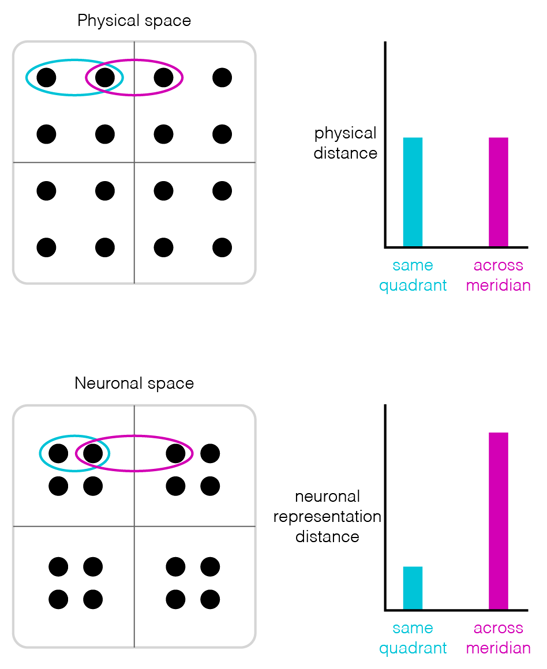
A quadrantic bias in prefrontal representation of visual-mnemonic space
ML Leavitt, F Pieper, AJ Sachs, JC Martinez-Trujillo
Cerebral Cortex (2017)
Accessible abstract: Working memory (WM), the temporary (milliseconds to seconds) maintenance and manipulation of information no longer available to the senses, is strongly correlated with measures of intelligence, and a critical foundation for complex behaviors. Psychophysical studies have shown that the horizontal and vertical meridians of the visual field can bias spatial information maintained in WM; remembered locations systematically drift away from the meridians. The lateral prefrontal cortex (LPFC) is known to encode WM representations of visual space, but previous experiments were not structured in a way that could examine the effects of meridians.
We found that when storing visual information in working memory, the contents of working memory are not a veridical representation of the external world. Instead, visual space during memory is divided into four quadrants, an effect we see both in neurons and in subjects’ behavior. Our results provide an explanation for known WM biases, and imply that what we remember, even moments after having seen it, has been transformed from what was really there.
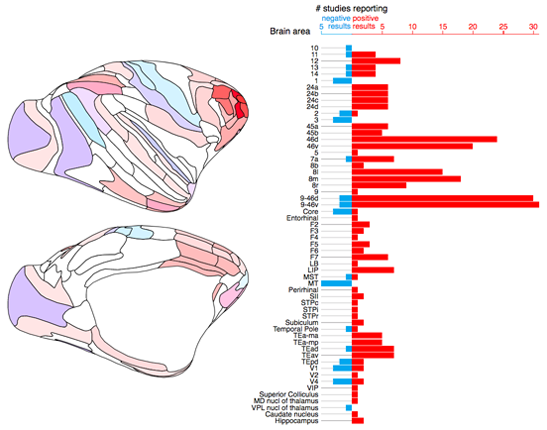
Sustained activity encoding working memories: not fully distributed
ML Leavitt, D Mendoza-Halliday, JC Martinez-Trujillo
Trends in Neurosciences (2017)
Accessible abstract: Any given behavior likely recruits many parts of the brain. Thus a major challenge in neuroscience is designing experiments that can precisely control for and dissociate the components of a behavior that rely on different neurons or brain regions. The same behavior may be studied in very different ways across different experiments, providing additional challenges when one tries to draw generalizations or integrate across studies. The study of working memory (WM) is certainly not exempt from these challenges.
Neuronal activity in the absence of stimulus input (i.e. neurons activating once the item to remember disappears) is widely considered to be a neural mechanism for WM. This phenomenon was once thought to be limited to certain regions of cortex, but a number of recent studies have argued that this sustained firing is a ubiquitous property of cortical neurons.
We investigated the evidence for WM activity across the cortex by conducting a comprehensive review of over 150 studies. We found robust evidence that prefrontal, parietal, and inferotemporal cortices (typically considered “higher” brain areas) exhibit sustained activity during WM tasks, whereas accounts of WM-related activity in early sensory areas are rare and strongly qualified. We also provide a compelling explanation for why fMRI studies often find the opposite result. I created an interactive brain map to convey the results from our review. We invite researchers to contribute to keeping it timely by notifying us of novel or overlooked studies.
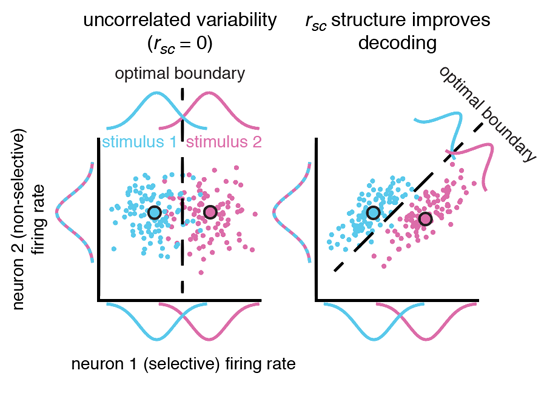
Correlated variability modifies working memory fidelity in primate prefrontal neuronal ensembles
ML Leavitt, F Pieper, AJ Sachs, JC Martinez-Trujillo
Proceedings of the National Academy of Sciences (2017)
Accessible abstract: Is the whole more than the sum of its parts? This question is surprisingly relevant to neuroscience. Neurophysiological experiments have traditionally involved recording from individual neurons serially, then aggregating these asynchronous measurements to derive conclusions about how the brain works. Thus it is extremely important to know, but remains poorly-understood how larger ensembles of simultaneously-recorded neurons encode information and give rise to behavior. Thankfully, recent technological advances have dramatically reduced the challenges of recording large numbers of neurons simultaneously in behaving animals.
We conducted an experiment to examine the role of network-level phenomena in spatial working memory (SWM) coding in prefrontal cortex (PFC). We used machine learning techniques to assess the information content of neuronal ensembles, and found a number of interesting discrepancies between single neuron and ensemble coding models of SWM. First, ensembles containing the strongest SWM signals are not always composed of the most informative single neurons. We also found that network effects (“noise correlations”) can dramatically alter the fidelity of SWM signals. Finally, we found that neurons that do not contain SWM information in isolation can still increase SWM information when part of an ensemble. This final result is especially relevant, as these “non-selective” neurons are traditionally overlooked by researchers and omitted from models and analyses.
More broadly, our results highlight limitations in the traditional neurophysiological method of examining neurons in isolation, emphasizing the relevance of ensemble-level phenomena in building a comprehensive understanding of the brain. Much can be lost when one attempts to describe a network by aggregating the properties of its constituent components.
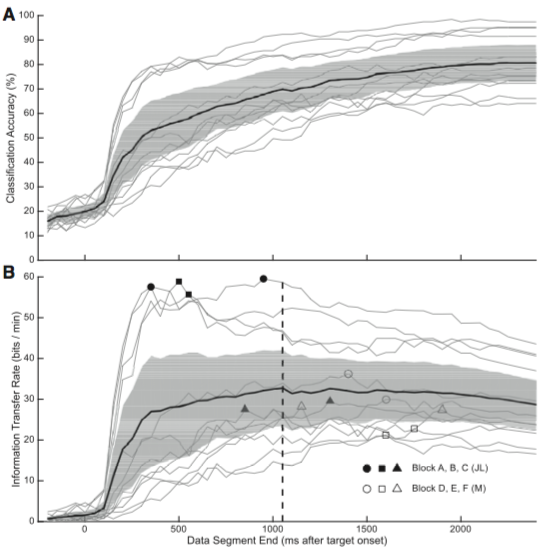
Single-trial decoding of intended eye movement goals from lateral prefrontal cortex neural ensembles
CB Boulay, F Pieper, M Leavitt, J Martinez-Trujillo, AJ Sachs
Journal of Neurophysiology (2015)
Accessible abstract: Recent advances in neural prosthetics research have made it such that controlling a robot arm with one’s brain activity is no longer a sci-fi pipedream. Most neural prosthetics decode signals from motor cortex and convert them into commands for effectors such as robot arms and computer cursors. Signals in motor cortex are effector-specific and immediate; “move your arm like this, right now”. The ability to decode intended goals in a more abstract form, prior to movement initiation could yield a uniquely powerful and flexible kind of neural prosthetic.
Neurons in the lateral prefrontal cortex (LPFC) encode signals for goal-directed actions, thus the LPFC might be a good signal source for such a goal-selection brain-computer interface (BCI). As a first step in the development of a goal-selection BCI, we set out to determine if we could decode simple behavioral intentions to direct gaze to different locations in space from LPFC neural activity. We compared a number of different decoding algorithms, and found that is indeed possible to decode intended saccade target location from single-trial LPFC activity. This suggests that the LPFC is a suitable region for a goal-selection (or cognitive) BCI.
Structure of spike count correlations reveals functional interactions between neurons in dorsolateral prefrontal cortex area 8a of behaving primates
ML Leavitt, F Pieper, AJ Sachs, JC Martinez-Trujillo
PLoS ONE (2013)
Accessible abstract: Neurons that process sensory information are often arranged topographically in the cortex. For example, neurons in visual cortex that fire in response to light at a given point in the visual field will lie adjacent on the cortical surface to neurons that respond to light at an adjacent point in the visual field. The connection strength between neurons within a given brain region typically follows this same pattern: neurons that have similar response preferences will be more strongly connected.
While this relationship between connection strength, response similarity, and anatomical distance is well-established across different regions of sensory cortex, it is unclear whether it also exists in the prefrontal cortex (PFC). There are two causes for this ambiguity: First, the PFC integrates information from a variety of different sensory modalities and brain regions, and accordingly the response properties of PFC neurons are often much less intuitive and more challenging to characterize than those of neurons in sensory cortex. Second, there are very few studies examining connection strength between PFC neurons, likely because doing so requires a researcher to record from multiple neurons simultaneously, which is methodologically challenging.
We leveraged the power of multielectrode arrays, which can record from many neurons simultaneously, to investigate functional connectivity between neurons in the PFC. We found that functional connectivity between PFC area 8a neurons depends on the physical distance between them and the relationship between their visuospatial tuning preferences, similar to what is observed in sensory cortex. Our results support the notion that the relationship between anatomical distance, tuning, and connectivity strength appears to be a general property of cortex.
